Conversations with a Document Store
I stayed up rather late writing some code for my MUD. When I finally went to sleep, I had an interesting dream involving a conversation with the idealized personification of MongoDB.
What the heck? How can one have a conversation with a NoSQL document store? Have you ever seen Transformers: The Movie (1986)? Do you remember the scene where Megatron encounters Unicron?
If you imagine that I was Megatron and MongoDB was Unicron, you won't be far off. However, our conversation was a little less contentious than the one Megatron and Unicron shared.
After I woke up, some of that conversation congealed into a cryptography idea.
Bath-Salted Password Hashing
If the idea turns out to be a good one, then I decided to call it Bath-Salted Password Hashing because it will make password crackers as angry as someone high on bath salts.
If the idea turns out to be a bad one, then people will say I must have come up with it while high on bath salts.
Note: I'm not sure if this idea has been proposed before. I've done some reading on salted password hashes, but I don't remember this proposal. Likely, it has been proposed and shot down as insecure before. If you have experience with cryptography or especially cryptanalysis, I would appreciate your feedback!
Password Storage - The Naive Approach
The problem we are trying to solve (and the problem I was working on with my MUD) is the problem of storing passwords for authentication. You've got a service hosted online and your users have an account registered with the service. You want to make sure that an account is only accessed by users who know a shared secret (i.e.: the password to the account).
So in your database, you store the account name and you store the password in plain text. When someone logs in, you check to see that the password they provided matches with what you have stored in your database.
| Account | Password |
|---|---|
| Alice | Michelle |
| Bob | bobrulz |
| Carol | DybubyeaHyd9 |
| Dave | bobsux |
This is simple and it works. However, there is a serious drawback to this solution: Every password is stored in plain text. One security breach and every account is instantly compromised. Even worse, people re-use their passwords on multiple services, and so all of those accounts are now compromised too.
So now when a user provides their password, we run it through the hash function and compare the output. If they match, they've provided the same password and we grant access. If not, we deny them access to the account.
Surely this is much better. If we have a security breach, the attacker can't see the passwords and the day is saved. Or, is it...?
https://duckduckgo.com/?q=ee17dc479d8eb9848d89de4ae67b526d
https://www.google.com/search?q=052f13c55882109205f02c240132259c
A quick search for the hash output gives us Alice's password and Dave's password. Well, that's certainly less than ideal.
In The Shield, there was a scene in Season 2 where Officer Shane Vandrell tells Officer Julian Lowe, "When it comes to your partner's career, the truth is like grits. You don't serve it up plain, you put a little salt on it."
To paraphrase Shane Vandrell:
When a user attempts to log in, we look up their salt value, append the provided password and feed that into the hash function. If the output matches, we grant access to the account. If not, we deny access to the account.
But what about a security breach? Try searching for those hash values. As of this writing, they don't lead to any results. (Of course, if Google decides to index this blog post, that'll blow this paragraph straight to hell, won't it?) So the day is saved. Or is it...?
https://en.wikipedia.org/wiki/Password_cracking
As you might guess, even salt is not the end of the story. If we use a simple scheme to salt the password (such as appending the password to a salt value) we make it harder for the attacker to simply look up the password.
However, this does not thwart clever attempts to guess the password by brute force. If an attacker knows that Dave is a high value account (maybe Dave is an administrator on the service and has access to special commands) they would start by computing the hash of the salt:
startingPoint = MD5("topNeum4")
Now they try to brute force Dave's password. Unfortunately, Dave has a rather short password ("bobsux") and it probably won't be long before it is broken.
You might ask: What if we add some more salt? Put some salt on the end of the password? Or in the middle of the password? Will that help?
Yes and no. Salt is not considered to be a secret. The prefix salt can still be used as a starting point, and salt in the middle or at the end just adds a few more computational steps in the cracking process. Here's an interesting article that goes into some more detail on that:
http://www.rhyous.com/2012/06/18/how-to-effectively-salt-a-password-stored-as-a-hash-in-a-database/
So yes, it helps to slow down the attacker a bit. But no, it doesn't provide an order of magnitude more help.
By estimating the computing resources of the attacker, we choose the number of iterations sufficiently high that testing even a small part of the password space is infeasible.
However, as the Wikipedia article points out, even PBKDF2 can be misused. A single iteration is really no stronger than a single hash. So if you intend to use PBKDF2, make sure that you use it correctly.
Wikipedia also references bcrypt and scrypt as members of this key expansion / key stretching family of salted password hashing algorithms.
I propose a "new" (at least to me) method of hashing salted passwords. I don't know if it is more secure than existing methods. I don't know if it requires more resources to crack than existing methods. Literally, this idea congealed in my head less than 24 hours ago. I write this post with two goals:
- Given P = a password, N bits in length
- Given X = a prefix salt, at least 2*N bytes in length
- Given Y = a postfix salt, at least 2*N bytes in length
- Given H = a strong hash function (for example, SHA-3 [as of this writing])
- Given I = an empty input buffer
Pseudo-Code Algorithm:
x = 0
y = 0
for i = 0 to (N-1)
b = P.bit(i)
if b == 0
I.push(X[x])
x++
else // b == 1
I.push(Y[y])
y++
I.push(X.slice(x,X.length))
I.push(P)
I.push(Y.slice(y,Y.length))
output = H(I)
Description:
For each bit of the password, we consume a byte of either the prefix salt or the postfix salt, depending on the value of the bit. The byte is appended to the input buffer.
After we have consumed N bytes (taken in an arbitrary order from the two salt values) we append the remainder of the prefix salt to the input buffer.
We then append the password to the input buffer.
We then append the remainder of the postfix salt to the input buffer.
The output is then the result of running the hash function on the input buffer.
Discussion:
The bits of the password are used to select the salt bytes that are used to construct the input buffer. Because the password could have an arbitrary length and bit content, the number of bytes, where they came from, the order in which they will appear will vary significantly between passwords.
Although the salt is not secret, the portion of it that becomes more password-like than salt-like is unknown to the attacker.
A possible improvement would be to run the password (unsalted) through a second distinct hash-function (call it H') to obtain P' and then truncate the number of bits to match the number of bits in the original password. The idea here would be to take a password with a (potentially guessable) lopsided number of 0s and 1s and convert it to something with a more even distribution of 0s and 1s. We truncate to retain the original bit length so as to deprive the attacker the knowledge of a fixed consumption of the salt values.
Let A be the number of iterations to run the password through H' during each iteration of the bath-salt algorithm.
For example, if A=5 then the inner-hash would be P' = H'(H'(H'(H'(H'(P)))))
Let B be the number of iterations to run the bath-salt algorithm
After computing the output of a bath-salt iteration, let Mutate_Index be the (log2(N)+1) bits from the LSB of the output. Mutate (xor 1) the bit at (index % N) of P. Now iterate B-1 more times.
Password Storage - The Slightly Better Approach
Instead of storing the password, we decide to store the hash of the password. A hash function is a mathematical function that scrambles up the input and attempts to provides a more-or-less unique value, a kind of fingerprint of the input if you will.| Account | Password |
|---|---|
| Alice | ee17dc479d8eb9848d89de4ae67b526d |
| Bob | 75ecf6c2761847d6bd1d356f3c4fafcd |
| Carol | 883380925f05df121f930e5fb7e27ced |
| Dave | 052f13c55882109205f02c240132259c |
So now when a user provides their password, we run it through the hash function and compare the output. If they match, they've provided the same password and we grant access. If not, we deny them access to the account.
Surely this is much better. If we have a security breach, the attacker can't see the passwords and the day is saved. Or, is it...?
https://duckduckgo.com/?q=ee17dc479d8eb9848d89de4ae67b526d
https://www.google.com/search?q=052f13c55882109205f02c240132259c
A quick search for the hash output gives us Alice's password and Dave's password. Well, that's certainly less than ideal.
Password Storage - The Somewhat Better Approach
I don't know if you've seen The Shield. It was an excellent television show (cop drama) that ran from 2002 to 2008. I watched it up until I moved to India in 2004 and I am just now (5 years on) trying to catch up to where I left off.In The Shield, there was a scene in Season 2 where Officer Shane Vandrell tells Officer Julian Lowe, "When it comes to your partner's career, the truth is like grits. You don't serve it up plain, you put a little salt on it."
To paraphrase Shane Vandrell:
When it comes to hash functions, passwords are like grits. You don't serve it up plain, you put a little salt on it.A salt is a bit of random data that you mix with the password before providing it to the hash function. The output then reflects the combination of the password and the salt value. So in our database, we'll generate a random salt for everybody and store it alongside the password.
| Account | Salt | Password |
|---|---|---|
| Alice | PeksOtt6 | 2566bb01cdf46637d85c314ca74800c5 |
| Bob | Jagwelv4 | 413c9255f6df8b2b5d10b8cdf773d3c3 |
| Carol | AvTohon1 | f6010835686677d7540b75e3a78be0f4 |
| Dave | topNeum4 | 0b6c8acd08fa79230c589d75b9974df2 |
When a user attempts to log in, we look up their salt value, append the provided password and feed that into the hash function. If the output matches, we grant access to the account. If not, we deny access to the account.
But what about a security breach? Try searching for those hash values. As of this writing, they don't lead to any results. (Of course, if Google decides to index this blog post, that'll blow this paragraph straight to hell, won't it?) So the day is saved. Or is it...?
https://en.wikipedia.org/wiki/Password_cracking
As you might guess, even salt is not the end of the story. If we use a simple scheme to salt the password (such as appending the password to a salt value) we make it harder for the attacker to simply look up the password.
However, this does not thwart clever attempts to guess the password by brute force. If an attacker knows that Dave is a high value account (maybe Dave is an administrator on the service and has access to special commands) they would start by computing the hash of the salt:
startingPoint = MD5("topNeum4")
Now they try to brute force Dave's password. Unfortunately, Dave has a rather short password ("bobsux") and it probably won't be long before it is broken.
You might ask: What if we add some more salt? Put some salt on the end of the password? Or in the middle of the password? Will that help?
Yes and no. Salt is not considered to be a secret. The prefix salt can still be used as a starting point, and salt in the middle or at the end just adds a few more computational steps in the cracking process. Here's an interesting article that goes into some more detail on that:
http://www.rhyous.com/2012/06/18/how-to-effectively-salt-a-password-stored-as-a-hash-in-a-database/
So yes, it helps to slow down the attacker a bit. But no, it doesn't provide an order of magnitude more help.
Password Storage - The Current State of the Art
Password-Based Key Derivation Function 2 (PBKDF2) uses several thousands of hash iterations. By applying the hash function repeatedly, the computation resources needed to hash a single password grows quite large.By estimating the computing resources of the attacker, we choose the number of iterations sufficiently high that testing even a small part of the password space is infeasible.
However, as the Wikipedia article points out, even PBKDF2 can be misused. A single iteration is really no stronger than a single hash. So if you intend to use PBKDF2, make sure that you use it correctly.
Wikipedia also references bcrypt and scrypt as members of this key expansion / key stretching family of salted password hashing algorithms.
Password Storage - Bath-Salted Password Hashing
You're still here? Oh good. This is where we get to the meat of this blog post.I propose a "new" (at least to me) method of hashing salted passwords. I don't know if it is more secure than existing methods. I don't know if it requires more resources to crack than existing methods. Literally, this idea congealed in my head less than 24 hours ago. I write this post with two goals:
- Communicate the Bath-Salted Password Hashing algorithm so that anybody could implement it in the language of their choice.
- Solicit feedback from cryptographers: Is this idea worth considering? Or is it a waste of time for reasons that are currently unknown to me?
- Given P = a password, N bits in length
- Given X = a prefix salt, at least 2*N bytes in length
- Given Y = a postfix salt, at least 2*N bytes in length
- Given H = a strong hash function (for example, SHA-3 [as of this writing])
- Given I = an empty input buffer
Pseudo-Code Algorithm:
x = 0
y = 0
for i = 0 to (N-1)
b = P.bit(i)
if b == 0
I.push(X[x])
x++
else // b == 1
I.push(Y[y])
y++
I.push(X.slice(x,X.length))
I.push(P)
I.push(Y.slice(y,Y.length))
output = H(I)
Description:
For each bit of the password, we consume a byte of either the prefix salt or the postfix salt, depending on the value of the bit. The byte is appended to the input buffer.
After we have consumed N bytes (taken in an arbitrary order from the two salt values) we append the remainder of the prefix salt to the input buffer.
We then append the password to the input buffer.
We then append the remainder of the postfix salt to the input buffer.
The output is then the result of running the hash function on the input buffer.
Discussion:
The bits of the password are used to select the salt bytes that are used to construct the input buffer. Because the password could have an arbitrary length and bit content, the number of bytes, where they came from, the order in which they will appear will vary significantly between passwords.
Although the salt is not secret, the portion of it that becomes more password-like than salt-like is unknown to the attacker.
A possible improvement would be to run the password (unsalted) through a second distinct hash-function (call it H') to obtain P' and then truncate the number of bits to match the number of bits in the original password. The idea here would be to take a password with a (potentially guessable) lopsided number of 0s and 1s and convert it to something with a more even distribution of 0s and 1s. We truncate to retain the original bit length so as to deprive the attacker the knowledge of a fixed consumption of the salt values.
Iterated Bath-Salted Password Hashing?
I'll admit that I haven't given much thought to iteration yet. But here's sketch of how I might start exploring it:
Let A be the number of iterations to run the password through H' during each iteration of the bath-salt algorithm.
For example, if A=5 then the inner-hash would be P' = H'(H'(H'(H'(H'(P)))))
Let B be the number of iterations to run the bath-salt algorithm
After computing the output of a bath-salt iteration, let Mutate_Index be the (log2(N)+1) bits from the LSB of the output. Mutate (xor 1) the bit at (index % N) of P. Now iterate B-1 more times.
More To Come
Unfortunately, I've already spent more time writing this blog post than I intended. My plan is to follow up next week with more specifics, including a Node / JavaScript / CoffeeScript implementation of these ideas.
Thank you for reading and many thanks in advance for any feedback!
 . The device parameters are:
. The device parameters are: 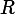


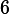
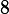
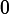

 ,
, 

 V.
V.

